Gemini 3.5 Flash costs 3x what Gemini 3 Flash did. Google priced it that way because it beats their own Pro model on agentic work.
Google shipped Gemini 3.5 Flash on May 19 at I/O 2026. The headline is the rate card: $1.50 input and $9 output per million, against $0.50 and $3 for the model it replaces. That is a flat tripling. The justification is on the benchmark sheet. On Terminal-Bench 2.1, MCP Atlas, GDPval-AA, and SWE-Bench Pro, the new Flash beats Gemini 3.1 Pro at 25 percent less per token. Flash is not the budget tier anymore. It is a frontier coding and agent model that happens to keep the Flash branding.

Image source: Google
The rate card, side by side with what it replaces
One table tells the whole pricing story. Standard tier, paid tier, every published Flash SKU from the last 60 days.
| Model | Input / 1M | Output / 1M | Cached | Context |
|---|---|---|---|---|
| Gemini 3.5 Flash (new) | $1.50 | $9.00 | $0.15 | 1M, flat |
| Gemini 3 Flash | $0.50 | $3.00 | $0.05 | 1M, flat |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | $0.025 | 1M, flat |
| Gemini 3.5 Flash Batch / Flex | $0.75 | $4.50 | $0.075 / $0.08 | 1M, flat |
| Gemini 3.5 Flash Priority | $2.70 | $16.20 | $0.27 | 1M, flat |
A few things worth pulling out. The Flex tier brings the standard rate back to where Gemini 3 Flash sat a week ago, which is the cleanest way to read Google's real cost floor on the new generation. The Priority tier is 80 percent above standard, which is what you pay for guaranteed throughput on agentic traffic. And Flash-Lite is now 6x cheaper than its bigger sibling, the widest intra-family gap Google has ever shipped on the Flash line.
Simon Willison ran the Artificial Analysis benchmark suite on both versions. Gemini 3 Flash cost $278.26 to run the suite. Gemini 3.5 Flash cost $1,551.60. That is 5.5x, not 3x, because the new model also spends more output tokens per agentic turn. If you are routing the same workload that ran on 3 Flash to 3.5 Flash, plan for somewhere between 3x and 5x on the bill.
Where it lands against the rest of the frontier
Standard rate against every published frontier card in May 2026. Two columns matter most: the per-1M cost and the surcharge structure, because the long-context bills are where models with innocent-looking rate cards start hurting.
| Model | Input / 1M | Output / 1M | Surcharge | 1M / 10K total |
|---|---|---|---|---|
| GPT-5.5 | $5.00 | $30.00 | 2x in / 1.5x out above 272K | $8.94 |
| Claude Opus 4.7 | $5.00 | $25.00 | Flat since March 13 | $5.25 |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2x in / 1.5x out above 200K | $3.78 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Flat, 1M context | $3.15 |
| Gemini 3.5 Flash | $1.50 | $9.00 | Flat, 1M context | $1.59 |
| Claude Haiku 4.5 | $1.00 | $5.00 | Flat | $1.05 |
| Grok 4.3 | $1.25 | $2.50 | Flat, 1M context | $1.28 |
On a 1M/10K shape, Gemini 3.5 Flash lands at $1.59. Opus 4.7 runs you about three-and-a-third times more for the same call. GPT-5.5 costs roughly six times as much once you cross the 272K surcharge line. Gemini 3.1 Pro under 200K is the closest competitor at $3.78, still more than double the bill. Sonnet 4.6 and Haiku 4.5 sit near it on cost, but Sonnet's output token is twice the price, and Haiku is a smaller model entirely. Only Grok 4.3 at $1.28 beats it, and that is the cheapest published rate card for any frontier-adjacent model in May 2026, full stop.
What is unusual here is Google undercutting its own Pro tier by 25 percent with a model that beats it on the benchmarks that matter to agentic developers. That used to be a strategic mistake big labs avoided. Google is leaning into it, presumably because Gemini 3.5 Pro ships next month and will reset the top of the stack.
Benchmarks: the agentic story is the whole story
Google published a dense scoresheet alongside the launch. The pattern across it is clear: 3.5 Flash beats 3.1 Pro on every agentic and coding metric, and loses on the pure reasoning ones. For developers shipping agents, that is the trade Google wants you to make.
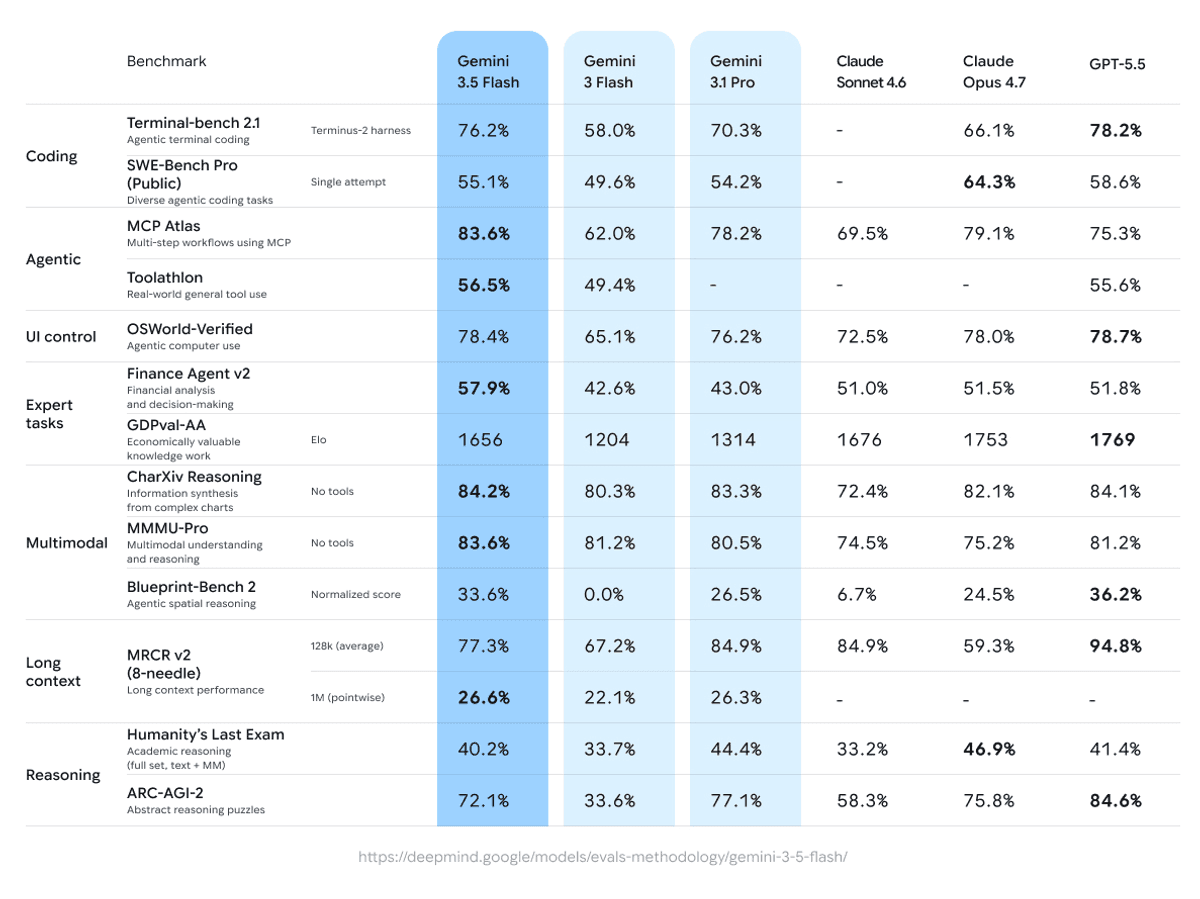
Benchmark chart from Google
| Benchmark | 3.5 Flash | 3.1 Pro | GPT-5.5 | Opus 4.7 |
|---|---|---|---|---|
| Terminal-Bench 2.1 | 76.2% | 70.3% | 78.2% | — |
| MCP Atlas (agentic tools) | 83.6% | 78.2% | 75.3% | 79.1% |
| SWE-Bench Pro (Public) | 55.1% | 54.2% | — | 64.3% |
| GDPval-AA (ELO) | 1656 | 1314 | — | 1753 |
| Finance Agent v2 | 57.9% | 43.0% | — | — |
| CharXiv Reasoning (multimodal) | 84.2% | 83.3% | 84.1% | — |
| Humanity's Last Exam | 40.2% | 44.4% | — | — |
| ARC-AGI-2 | 72.1% | 77.1% | — | — |
| Output speed (tok/s) | ~289 | ~70 | ~140 | ~98 |
Read the GDPval-AA row first. The new Flash jumps 342 ELO points over Gemini 3.1 Pro on real-world task performance, which is the biggest single-generation lift Google has posted on that benchmark. On MCP Atlas it leads the entire reported field, including Opus 4.7. On Finance Agent v2 it almost lifts 15 points over 3.1 Pro. That is not a small model wearing Flash branding, it is a midweight model architected for tool use.
The losses are real and worth naming. On Humanity's Last Exam, the pure reasoning benchmark, 3.1 Pro is 4.2 points ahead. On ARC-AGI-2, also reasoning-shaped, 3.1 Pro is 5 points ahead. On SWE-Bench Pro, Opus 4.7 still leads by 9.2 points. If the workload is hard logic puzzles or the very top of autonomous coding, the new Flash is not where you go. For everything else on this table, it now is.
Cached pricing turns the 3x hike into a 50 percent bill cut
The implicit caching tier is the lever most people will not pull until they look at a bill. At $0.15 per million cached input tokens, Gemini 3.5 Flash gives you the steepest cache discount in the Google lineup. Run a workload with a stable system prompt and heavy context reuse, and the per-call math gets unrecognizable fast.
| Scenario (10M input, 1M output) | No cache | 90% cache hit | Cache savings |
|---|---|---|---|
| Gemini 3.5 Flash | $24.00 | $11.85 | 50.6% |
| Gemini 3 Flash | $8.00 | $3.95 | 50.6% |
| Claude Opus 4.7 | $75.00 | $34.50 | 54.0% |
| GPT-5.5 (under 272K assumed) | $80.00 | $39.50 | 50.6% |
With caching on, Gemini 3.5 Flash at $11.85 for a 10M/1M workload costs about a third of cached Opus 4.7 and roughly 30 percent of cached GPT-5.5. The cache flips the comparison entirely. Workloads that look painful at the standard rate become routine once you front the implicit cache and let it amortize across calls.
The thinking_level parameter is the new control surface
Quiet API change worth flagging. The old integer thinking_budget knob is gone. Gemini 3.5 Flash takes a string enum: minimal, low, medium (default), high. Google retuned the low level specifically for coding and agent traffic, which is the explicit signal that they expect most agent developers to hold thinking down and let the underlying model speed do the work. At 289 tokens per second of output, holding thinking at low is how you get the latency that the rate card paid for.
High thinking mode bills the same as low. The throttle is on latency and quality, not on price. For an OpenAI translation, think of thinking_level low as roughly what reasoning_effort low gets you on o-series, but Google is the first to set the agentic-low tier as a tuned default rather than a leftover from the reasoning ladder.
What to do with this on Monday
Two routes get cheaper, one gets more expensive, and the budget tier did not move.
Agent traffic currently on Gemini 3.1 Pro at $2/$12 is the cleanest migration. Switching to 3.5 Flash at $1.50/$9 saves a quarter on the bill and the benchmark sheet says you gain on MCP Atlas, Terminal-Bench, and GDPval-AA at the same time. One config line, measurable upside. The narrow risk is workloads that lean on the reasoning benchmarks where 3.1 Pro still leads, and that bucket is smaller than most teams assume.
Cheap summarization, classification, or single-shot extraction currently running on Gemini 3 Flash at $0.50/$3 should stay there. The old model still serves that workload fine, and 3.5 Flash will silently triple the bill while delivering no measurable improvement on those task shapes. The agent unlock is the only thing that justifies the new price, and completions do not need it.
Teams paying GPT-5.5 or Opus 4.7 rates for tool-heavy traffic should run a shadow eval against 3.5 Flash before the next billing cycle closes. The MCP Atlas number says Google shipped the new agent-tier leader. The Finance Agent score backs it up. The actual question is whether your eval suite agrees, and the cheapest way to find out is to send 10 percent of the traffic through the new endpoint and compare. We would not assume the switch lands clean on every workload, but the math on the workloads where it does land is severe enough that the test cost is rounding error.
The thing that did not change: budget routes. Gemini 3.1 Flash-Lite at $0.25/$1.50 is still the cheapest published Flash-line model, and it now runs at roughly a sixth of the 3.5 Flash rate. For high-volume cheap traffic the Lite tier is the right answer. For everything in the middle, Google rearranged the menu. The pricing page has every frontier card side-by-side, and the calculator runs the math for any mix. For the previous Gemini 3 Flash launch context, see the April 19 Flash piece, and for the wider Gemini 3.1 Pro picture see the 3.1 Pro write-up.
Sources
- Google: Gemini 3.5 launch post - May 19, 2026 I/O announcement and benchmark sheet
- Google: Gemini API pricing - $1.50/$9 standard, $0.15 cached, Batch / Flex / Priority tiers
- Google DeepMind: Gemini 3.5 Flash model card - Full benchmark sheet with Terminal-Bench, MCP Atlas, GDPval-AA
- Simon Willison: Gemini 3.5 Flash - $278 vs $1,551 AA benchmark suite cost comparison
- llm-stats: Gemini 3.5 Flash launch - Pricing tiers, thinking_level parameter change, throughput
- TechTimes: Google ships 3.5 Flash - 3x price headline coverage, agentic positioning
- Constellation Research: 3.5 Flash launch analysis - Token cost vs performance framing
- OpenAI: API pricing - GPT-5.5 $5/$30 under 272K, 2x input / 1.5x output above
- Anthropic: Claude pricing - Opus 4.7 $5/$25, Sonnet 4.6 $3/$15, Haiku 4.5 $1/$5