Gemini Embedding 2: Pricing, limits, and how it compares to OpenAI
Google released a new embedding model yesterday. Unlike anything else on the market, it handles text, images, audio, video, and PDFs in a single vector space. Here's what it actually costs and whether it's worth considering.

Image source: Google Blog
TL;DR
- -Model:
gemini-embedding-2-preview, released March 10, 2026. - -Text pricing: $0.20 per 1M tokens. Batch: $0.10 per 1M.
- -Multimodal: Text, images, audio, video, and PDFs. All in one vector space.
- -Token limit: 8,192 input tokens (up from 2,048 on the previous model).
- -Dimensions: Matryoshka support, 128 to 3,072. Use 768 for a good balance of quality and storage.
Full pricing breakdown
The text price went up from $0.15 to $0.20 per million tokens compared to gemini-embedding-001. That's a 33% increase. But you also get 4x the input length and multimodal support, so it's not a straight comparison.
Here's the full breakdown by modality, straight from Google's pricing page:
| Modality | Paid | Batch (50% off) |
|---|---|---|
| Text | $0.20 / 1M tokens | $0.10 / 1M tokens |
| Images | $0.45 / 1M tokens | $0.225 / 1M tokens |
| Audio | $6.50 / 1M tokens | $3.25 / 1M tokens |
| Video | $12.00 / 1M tokens | $6.00 / 1M tokens |
There's also a free tier with rate limits. Good for testing, not for production. Audio and video pricing is steep, which makes sense since those inputs get tokenized into a lot more tokens than plain text.
How it compares to OpenAI
If you're building a text-only RAG pipeline and cost is what matters, OpenAI is still cheaper. Significantly cheaper. But the comparison gets more interesting when you need multimodal search.
| Model | Price / 1M tokens | Max input | Dimensions | Multimodal |
|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 8,192 | 128-3,072 | Text, image, audio, video, PDF |
| Gemini Embedding 001 | $0.15 | 2,048 | 768-3,072 | Text only |
| OpenAI text-embedding-3-large | $0.13 | 8,191 | 256-3,072 | Text only |
| OpenAI text-embedding-3-small | $0.02 | 8,191 | 512-1,536 | Text only |
OpenAI's text-embedding-3-small is 10x cheaper for text. If that's all you need, it's hard to justify the Gemini pricing on cost alone. The text-embedding-3-large is closer at $0.13 vs $0.20, and there you're paying for Google's quality edge on the MTEB leaderboard.
Where Gemini Embedding 2 has no real competition is multimodal. If you want to embed product images alongside their descriptions, or index video clips for semantic search, there isn't an equivalent from OpenAI right now. You'd need separate models (CLIP for images, Whisper + embeddings for audio) and deal with aligning the vector spaces yourself. Gemini handles it natively.
Benchmark scores
Google published benchmark results across text, image, video, and multilingual tasks. Gemini Embedding 2 leads on most metrics, particularly on MTEB Multilingual (69.9) and MTEB Code (84.0). Here's the full comparison from their announcement:
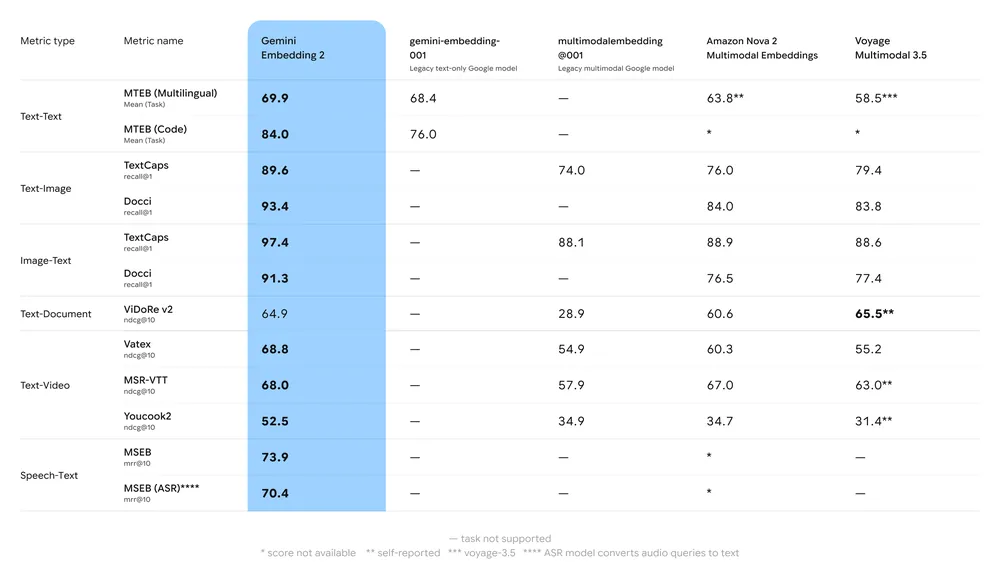
Source: Google Blog
The interesting numbers are in the multimodal columns. On video retrieval (Vatex, MSR-VTT, Youcook2), it outperforms everything else by a wide margin. On image benchmarks like TextCaps and Docci, it's competitive with Voyage Multimodal 3.5. For text-only MTEB, the gap between Gemini and the competition is smaller, but still there.
Which dimension size should you use?
Gemini Embedding 2 supports Matryoshka Representation Learning, which means you can truncate the output vector to any size between 128 and 3,072. Smaller vectors are cheaper to store and faster to search, with some quality trade-off.
Google recommends 768 dimensions as the sweet spot. According to their docs, 768 delivers "near-peak quality at roughly one-quarter the storage footprint of 3,072 dimensions." That matches what we see in the MTEB numbers too. The quality difference between 768 and 3,072 is minimal.
Quick math: 1 million vectors at 3,072 dimensions (float32) is about 12 GB. At 768 dimensions, that's 3 GB. Same cost to embed, but 4x less storage and 4x faster similarity search.
What changed from gemini-embedding-001
The previous model, gemini-embedding-001, launched in July 2025 and was text-only with a 2,048 token limit at $0.15 per million tokens. Here's what's different:
The 4x input length increase is probably the bigger deal for most text-only use cases. Longer chunks mean fewer splits, fewer overlaps, and better retrieval quality in RAG pipelines. Whether that's worth the 33% price bump depends on your volume.
When to use which model
There isn't a single right answer. It depends on what you're building:
Worth knowing
The model ID is gemini-embedding-2-preview. That "preview" tag means Google could change pricing or behavior before GA. They did this with the previous embedding model too, and the GA version was the same price, but worth keeping in mind.
Image inputs are capped at 6 per request. Audio at 80 seconds. Video at 128 seconds. PDFs at 6 pages. These limits are fine for indexing individual items but you'll hit them if you try to batch large documents in a single call.
Also: the old text-embedding-004 model is shutting down January 14, 2026. If you're still on that, this is probably a good time to move to either gemini-embedding-001 or Embedding 2.
Bottom line
For text-only embeddings, OpenAI is still the cheaper option. text-embedding-3-small at $0.02 per million tokens is hard to beat on price, and text-embedding-3-large matches Gemini on quality at $0.13.
What Gemini Embedding 2 does that nobody else does is multimodal embedding in a single model. If your search needs to span images, audio, or video, this is the simplest option available. Compare every embedding model side by side on our embedding pricing page, or estimate your monthly costs with the cost calculator.
Sources
- Google Blog: Gemini Embedding 2 (March 10, 2026)
- Gemini API Pricing (official pricing page)
- Gemini Embeddings Documentation (dimensions, limits, and usage)
- Gemini Embedding 2 Model Card (token limits, supported modalities)