Llama 4 Scout vs Maverick: API pricing, self-hosting costs, and which one to use
Maverick scores 69.8 on GPQA Diamond and costs $0.15 per million input tokens at DeepInfra. Scout has a 10-million-token context window and runs on a single H100. Both have 17B active parameters. Here is the full pricing breakdown across providers, plus the self-hosting math.
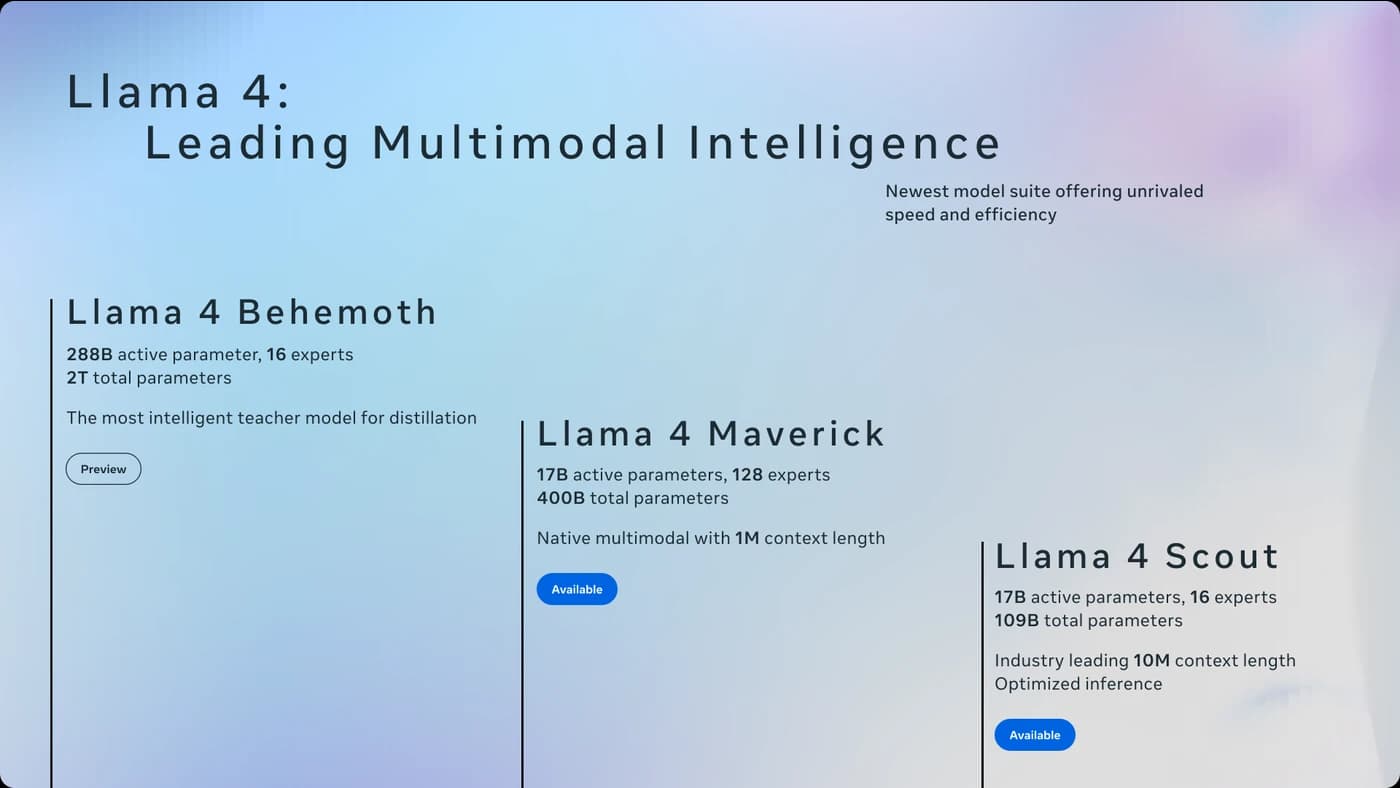
Image source: Meta AI
Quick numbers
- -Scout API cheapest: $0.08 input / $0.30 output per 1M tokens (DeepInfra). 17B active params, 109B total.
- -Maverick API cheapest: $0.15 input / $0.60 output per 1M tokens (DeepInfra / Fireworks). 17B active params, 400B total.
- -Context windows: Scout is 10M tokens natively (providers cap at 128K-320K). Maverick is 1M.
- -Self-hosting: Scout needs 1x H100 (~$2,500/month on-demand). Maverick needs 8x H100 (~$20,000/month).
- -License: Llama 4 Community License, not Apache 2.0. Commercial use is free for most; 700M+ MAU platforms need a separate Meta agreement.
Why both models have the same active parameter count
Scout is 109 billion parameters total. Maverick is 400 billion. But inference cost is driven by active parameters, and both activate exactly 17B per token. That gap is the MoE architecture: each token gets routed to one expert out of the pool, and the rest sit idle.
Each token gets routed to 1 of 16 experts in Scout, or 1 of 128 in Maverick, plus a shared expert in both cases. The larger pool gives Maverick more specialized knowledge without changing per-token compute. Meta also trained Maverick through codistillation from Behemoth, their 2-trillion-parameter teacher model. That's the most likely explanation for why Maverick outperforms models with comparable active parameter counts on hard reasoning tasks.
Scout's design trades expert depth for context. The iRoPE architecture uses interleaved attention layers with no positional encoding. Most layers use standard RoPE; the interleaved ones generalize beyond the 256K training window at inference via attention temperature scaling. Meta validated it with needle-in-haystack tests at 10M tokens and describes the long-term goal as "infinite" context.
API pricing across providers
Meta's direct Llama API is still waitlisted as of March 2026. Third-party providers are the practical option. There is meaningful price variation, and the available context window differs by provider even for the same model.
Llama 4 Scout (17Bx16E, 109B total)
| Provider | Input / 1M | Output / 1M | Max context | Notes |
|---|---|---|---|---|
| DeepInfra | $0.08 | $0.30 | 320K | |
| Groq | $0.11 | $0.34 | 128K | 594 tokens/sec |
| Fireworks AI | $0.15 | $0.60 | ~1M | On-demand only |
Llama 4 Maverick (17Bx128E, 400B total)
| Provider | Input / 1M | Output / 1M | Max context | Notes |
|---|---|---|---|---|
| DeepInfra | $0.15 | $0.60 | 1M | FP8 |
| Fireworks AI | $0.15 | $0.60 | ~1M | On-demand only, FP8 |
| Together AI | $0.27 | $0.85 | 1M | FP8, serverless |
Groq hosts Scout only (not Maverick). Together AI has Maverick on serverless but Scout is absent. Replicate uses time-based billing so direct token comparisons are not practical. Prices retrieved March 26, 2026. See our pricing page for updates.
What the benchmarks show
Meta's official model card compared Scout and Maverick against Llama 3.3 70B and Llama 3.1 405B, not GPT-4o directly. The release blog makes the GPT-4o claim in text. Here are the actual numbers from the model card, which is what you can verify.
| Benchmark | Scout | Maverick | Llama 3.1 405B |
|---|---|---|---|
| GPQA Diamond | 57.2% | 69.8% | 49.0% |
| MMLU Pro | 74.3% | 80.5% | 73.4% |
| MMMU (vision) | 69.4 | 73.4 | n/a |
| LiveCodeBench | 32.8% | 43.4% | 27.7% |
| MathVista | 70.7 | 73.7 | n/a |
| LMArena ELO | n/a | 1417 | n/a |
Maverick's 69.8 GPQA Diamond and LMArena ELO of 1417 (from the "experimental chat version" per Meta) put it in the same range as GPT-4o. Scout's scores are solid for a budget model but clearly one tier below. The 20-point LiveCodeBench gap between them (32.8 vs 43.4) is worth noting if coding is your main use case. Independent testing by the LMArena leaderboard team placed Maverick's experimental version at 1417 ELO - above the standard GPT-4o but below GPT-4o-mini-high and the current frontier.
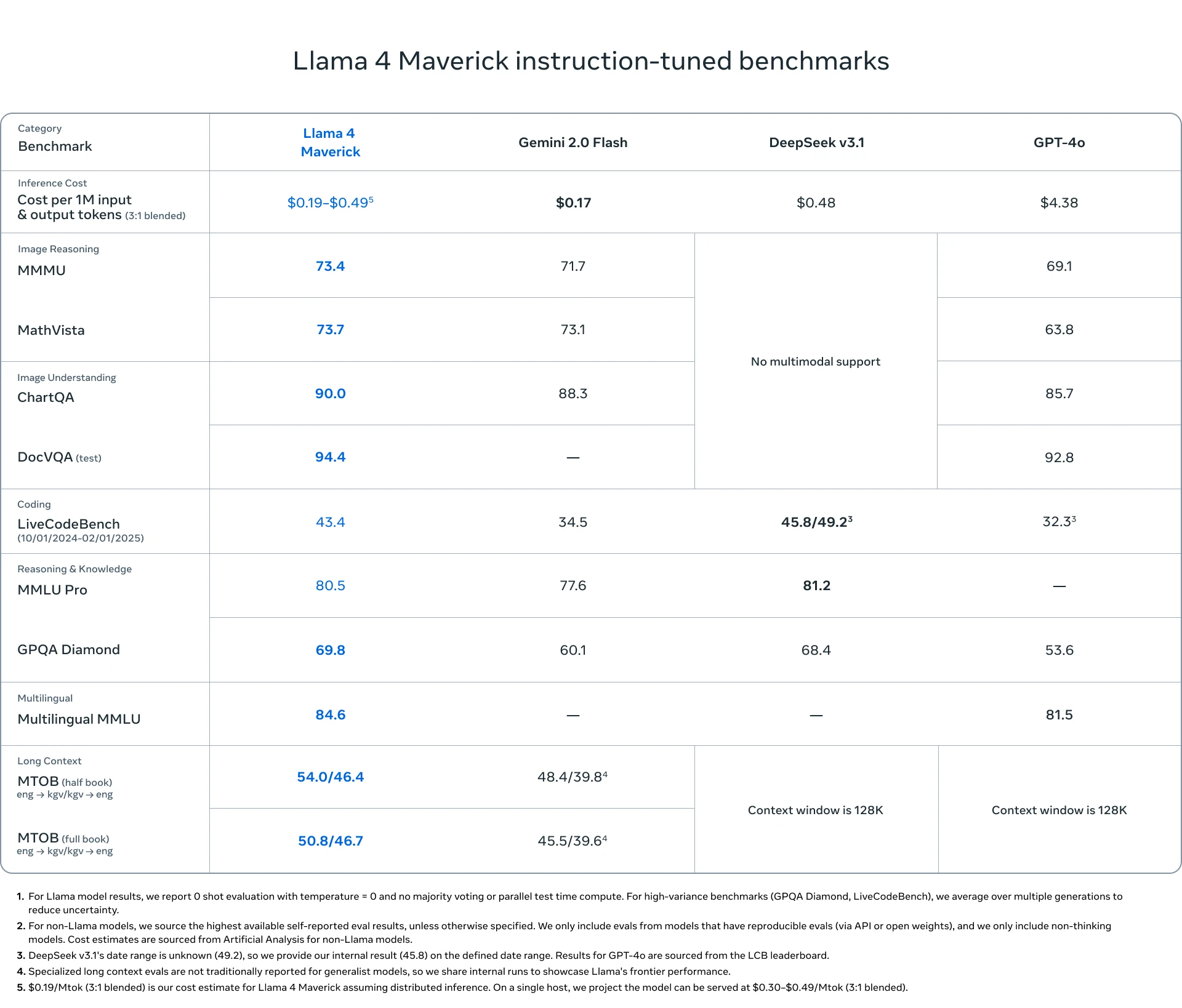
Image source: Meta AI
Self-hosting cost math
Scout (109B) fits on a single H100 80GB with int4 quantization (~54GB VRAM). Maverick with FP8 quantization needs a full DGX host: 8x H100s with 640GB combined VRAM. The hardware requirements are very different.
$3.49/hr at Together AI GPU cloud x 730 hrs
$2.25/hr reserved rate x 730 hrs
8 x $3.49/hr x 730 hrs
The breakeven numbers are large. 32 billion input tokens per month is roughly 1 billion tokens per day - sustained traffic of about 12,000 tokens per second. Maverick's 136B token breakeven is even further out of reach for most applications.
Self-hosting makes sense when you have data residency requirements, need Scout's full 10M context that providers cap, or are genuinely at hyperscale token volumes. Saving money at 10M tokens per month is not a realistic reason; the API wins by a large margin at that scale.
Scout's 10M context: the provider gap
Scout's native 10M context is real, but most providers do not expose it. Groq caps at 128K. DeepInfra at 320K. Fireworks at approximately 1M. The full 10M is only available when you self-host.
For long-document work, Scout at $0.08/M input is still the cheapest option by a significant margin. Gemini 3.1 Flash-Lite charges $0.25/M for 1M context. Claude Sonnet 4.6 charges $3.00/M (Anthropic removed the long-context surcharge earlier this year). Scout undercuts both, even capped at 320K.
If you genuinely need multi-million token context and cannot self-host, Gemini 3.1 Flash-Lite at $0.25/M is the most practical hosted option right now. Scout's provider caps make the 10M context more of a self-hosted research feature than an operational one for most teams.
Which one fits your workload
- You need the cheapest multimodal input ($0.08/M at DeepInfra)
- Speed is the priority (Groq runs it at 594 tokens/sec)
- You're processing documents under 320K tokens
- Self-hosting on a single H100 is viable for your setup
- GPT-4o quality is the target and GPT-4o prices are not
- Coding tasks where a 10-point LiveCodeBench gap matters
- Complex reasoning where Behemoth codistillation helps
- 1M context with stronger instruction following than Scout
Neither model supports audio. Both support text and images natively (trained on both from pretraining, not added later). Knowledge cutoff is August 2024 for both. Worth keeping in mind for anything time-sensitive without a retrieval layer in front.
The license is not Apache 2.0
This comes up constantly. Llama 4 uses the Llama 4 Community License. For most developers and companies it works like a permissive commercial license: you can use it commercially, fine-tune it, and redistribute derivatives.
The restriction is the 700M monthly active user threshold. Platforms above that size need a separate license from Meta. That exists to keep WhatsApp-scale consumer deployments under Meta's terms. For developer tooling, APIs, or enterprise applications, it is not a practical constraint.
Worth switching from GPT-4o?
Maverick at $0.15/M input is a strong case for anything currently running on GPT-4o. The 69.8 GPQA Diamond score and 1417 ELO are competitive, and the price difference versus most GPT-4o providers is significant. Run your own evals on your specific workload, but the headline argument for switching is real.
Scout is more specialized. The $0.08/M input price is the cheapest we track right now for a model with multimodal support and a real long-context architecture. But the gap between "10M native context" and "128K on Groq" is substantial. Check what your provider actually exposes before making decisions based on the 10M number.
Self-hosting either model only makes financial sense at tens of billions of tokens per month, or when you have other constraints like data residency. The API is the right default for almost everyone.
Sources
- Meta AI: Introducing Llama 4 (April 5, 2025)
- Meta Llama 4 Model Card - benchmark data and architecture details
- HuggingFace: Llama 4 Scout 17B-16E Instruct
- HuggingFace: Llama 4 Maverick 17B-128E Instruct
- Groq pricing
- DeepInfra pricing
- Fireworks AI pricing
- Together AI pricing