MiniMax M2.7 lists at $0.30 input, $1.20 output. The GDPval-AA score is the highest open-weight number on the board. The SWE-Bench Verified column is empty, and that is the story.
MiniMax shipped M2.7 on March 18. Two months in, the per-token price has not moved and the benchmark sheet pulls in two directions at once. M2.7 posts the highest GDPval-AA ELO of any open-weight model at 1509, ahead of Kimi K2.6 (1483) and every other open-weight entry. On SWE-Bench Pro it lands at 56.22, well behind Kimi K2.6 (58.6) and Claude Opus 4.7 (64.3). On SWE-Bench Verified the official scoresheet is blank. If you route agentic coding traffic, M2.7 is a different shape of bet than the rest of the open-weight tier. Here is the math.

Image source: MiniMax
The pricing, with the part MiniMax does not publish itself
MiniMax's own pricing page sells subscription tiers (requests per five hour window, fixed monthly fees). Per-token rates only surface on third-party aggregators and the OpenRouter listing. That matters when you size a contract, because the cheapest path to M2.7 is not the MiniMax dashboard. It is OpenRouter or the API spec their Hugging Face docs link.
| Endpoint | Input / 1M | Output / 1M | Cached input | Context |
|---|---|---|---|---|
| OpenRouter | $0.279 | $1.20 | n/p | 197K |
| MiniMax direct (per AA) | $0.30 | $1.20 | ~$0.06 | 205K |
| MiniMax subscription | flat tier | flat tier | n/p | 205K |
The cached-input rate is the soft spot in this table. MiniMax's prompt caching documentation lists the feature but their own pricing page does not translate cache hits to a dollar number. Aggregators report roughly $0.06 per million on cache reads, which is an 80% discount and consistent with the rest of the Chinese coding tier. If you run an agent with a stable system prompt and a heavy tool schema, that is where the real bill lands. Treat the cache number as semi-confirmed until MiniMax states it explicitly.
What MiniMax published, and what they did not
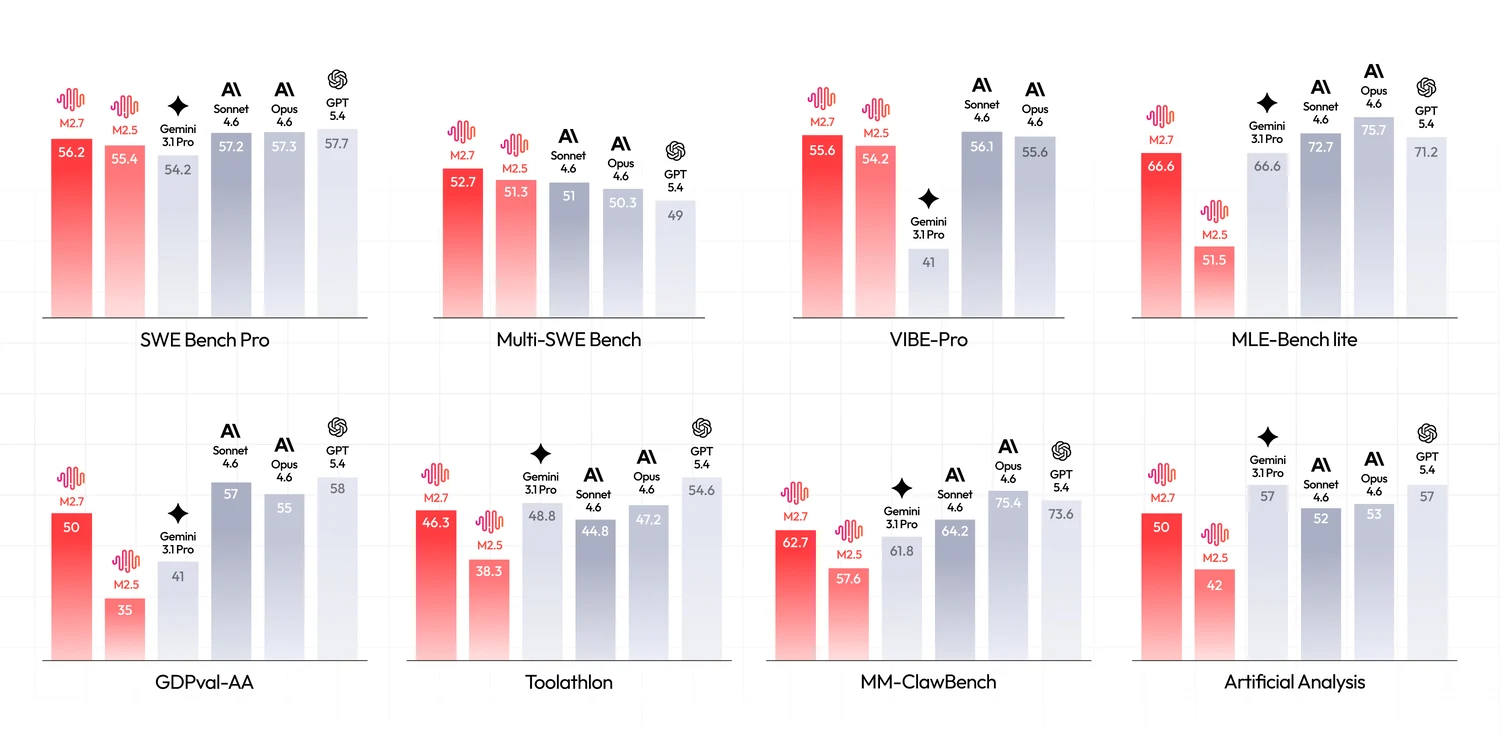
The benchmark page from the launch is a long list of agentic coding and tool-use scores, and a much shorter list of the classic reasoning benchmarks. The absence is deliberate. M2.7 is targeted at agentic coding work and the scoresheet reflects that decision.
| Benchmark | M2.7 | Kimi K2.6 | Opus 4.7 |
|---|---|---|---|
| SWE-Bench Verified | not published | 80.2 | 87.6 |
| SWE-Bench Pro | 56.22 | 58.6 | 64.3 |
| SWE-Bench Multilingual | 76.5 | 76.7 | n/p |
| Multi-SWE-Bench | 52.7 | n/p | n/p |
| Terminal-Bench 2 | 57.0 | 66.7 | 78.2 |
| GDPval-AA ELO | 1509 | 1483 | 1753 |
| MLE-Bench Lite (medal) | 66.6 | n/p | n/p |
| Toolathon | 46.3 | n/p | n/p |
| AA Intelligence Index | 50 | 54 | 63 |
The picture is consistent. M2.7 trails on classic reasoning benchmarks (AA Intelligence Index 50 versus Kimi 54, Opus 63) and on the harder agentic coding ones (SWE-Bench Pro and Terminal-Bench 2). It leads when the benchmark is multilingual coding, multi-repo coding, or anything that maps to ML-engineering workflows. The MLE-Bench Lite medal rate of 66.6 is the kind of score frontier closed models occupy. Among open weights, M2.7 is alone up there.
About that missing SWE-Bench Verified row: M2.5 (the prior release in the same family) scored 80.2 on Verified earlier this year. M2.7 was meant to be a broader-skill follow-up, with the announcement leaning hard on agentic coding, tool use, and ML engineering. A third-party claim of 78% circulated on social media but does not appear in MiniMax's own materials. Until MiniMax runs it, treat M2.7 on SWE-Bench Verified as unknown. The omission is the gap that matters when you compare against Kimi or Opus 4.7, both of which lead with their Verified number.
The GDPval-AA result is the part to stare at
GDPval-AA is Artificial Analysis's economic-value benchmark. It scores how useful an LLM's output is on tasks that match professional categories with measurable GDP contribution (research synthesis, code review, accounting workflows, legal analysis, ML engineering). The board uses an ELO format with head-to-head pairings judged by a separate frontier model. M2.7 at 1509 ELO leads every other open-weight entry. The next open-weight model down is Kimi K2.6 at 1483.
The closed frontier still pulls clearly ahead. Claude Opus 4.7 sits at 1753, which is a 244-point gap, not a sliver. That is real quality money. But the input-cost ratio is roughly 17 to 1 in M2.7's favor, so the price-per-ELO math runs hard in the open-weight direction. For workloads where you can route most traffic to a cheap model and reserve the closed frontier for the harder tail, M2.7 is the strongest open-weight pick on the board.
Caveat that bears repeating: GDPval-AA is a relatively young benchmark, the judge model bias is non-zero, and the methodology is closer to LMArena than to SWE-Bench. Read it as a signal, not as a verdict. The signal still says M2.7 is the open-weight model that punches hardest above its parameter count.
Cost per task vs the rest of the agentic coding tier
Three workload shapes, with M2.7 alongside the models you would otherwise route an agentic loop to. DeepSeek V4 Pro is shown at both promo and post-promo pricing because the promo ends May 31 and the math changes hard at that point.
| Workload | M2.7 | Kimi K2.6 (Moonshot) | DeepSeek V4 Pro (promo) | DeepSeek V4 Pro (post) | GPT-5.5 |
|---|---|---|---|---|---|
| Agentic turn (50K in / 10K out) | $0.027 | $0.055 | $0.030 | $0.122 | $0.550 |
| Big refactor (200K in / 30K out) | $0.096 | $0.195 | $0.113 | $0.453 | $1.900 |
| 1B tokens / month (70 / 30 blend) | $570 | $1,170 | $566 | $2,262 | $12,500 |
Three things jump out. First, M2.7 runs at roughly half the cost of Kimi K2.6 on every shape. Second, DeepSeek V4 Pro at promo pricing essentially ties M2.7 at the 1B-token monthly mark, but the promo ends in two weeks and the post-promo number runs about four times what M2.7 charges. Third, the GPT-5.5 column lives roughly an order of magnitude or two above M2.7, depending on output share. If your routing tier already lives with Kimi or Qwen3 Coder Next as the cheap leg, M2.7 slots in between them at a different quality profile.
The cached-input tier changes the agentic-turn math more than anything else. A typical coding agent with a 5K-token system prompt and a 30K-token tool schema sees roughly 70% of input tokens served from cache after the first turn. At $0.06 cached and $0.30 fresh, the effective input rate for a long session lands near $0.13 per million. That puts M2.7's agentic-turn bill below DeepSeek V4 Pro promo on every continuation. Worth confirming the cache rate before betting on it.
Routing M2.7, by workload type
One paragraph per workload type that matters. Verdicts in plain English at the end of each.
ML engineering loops. MLE-Bench Lite at 66.6% medal rate is the standout open-weight result on the M2.7 scoresheet. Auto-ML workflows, hyperparameter searches, notebook-style data-science tasks, and error analysis loops all land in M2.7's wheelhouse. The closed models that beat it here all charge an order of magnitude more per token. Route this work to M2.7.
Multilingual or multi-repo coding. SWE-Bench Multilingual at 76.5 essentially ties Kimi K2.6's 76.7 at half the published price on Moonshot direct. Multi-SWE-Bench at 52.7 is one of the few open-weight scores on that board. For repos with non-ASCII identifier patterns, Chinese / Japanese / Korean comment density, or cross-service refactors that span multiple repositories, M2.7 is the cheapest competent option. Route here.
Long-session agentic loops with cache. 197K context plus an $0.06 cached input rate means a long-running session with a stable system prompt costs effectively nothing on input after the first turn. Output stays at $1.20, still half of Kimi's Moonshot rate. If your agent has a heavy tool schema and a system prompt longer than 5K tokens, M2.7 is the value-tier pick. Route here, but verify cache pricing before committing.
Terminal-driven autonomous agents. Terminal-Bench 2 at 57.0 is fine, not great. Kimi K2.6 and Claude Opus 4.7 both report higher scores on that benchmark. If the agent owns shell sessions, environment setup, and long-horizon terminal work, the gap shows up as failed runs. Route to Kimi K2.6 or pay the premium for the closed frontier.
Pure SWE-Bench Verified work. Without an officially published score from MiniMax, M2.7 is hard to size against Kimi K2.6 at 80.2 or Opus 4.7 at 87.6 on this benchmark. For workloads where Verified is the KPI on your contract, route to Kimi K2.6 until MiniMax publishes a number for M2.7.
Reasoning-heavy non-coding tasks. AA Intelligence Index 50 puts M2.7 in the open-weight middle of the pack on a composite reasoning measure. Math-heavy work, formal logic, and long-form structured reasoning still favor the closed frontier as a class. Route to Gemini 3.1 Pro or Opus 4.7 if reasoning quality is the bar.
Whole-repo loads past 200K context. OpenRouter caps M2.7 at 197K. MiniMax direct lists 205K. Both numbers sit well below the 1M ceilings on Gemini 3.1 Pro, GPT-5.5, and Claude Opus 4.7. For agents that load a 500K-token codebase into context every turn, route somewhere with the headroom.
Practical aside on self-hosted throughput: 230B total with 10B active is a different operational shape than a dense 70-130B model. Total VRAM is larger, but tokens per second per GPU is higher because the MoE routing only fires a sliver of the parameters per forward pass. For inference budgets where latency matters more than VRAM headroom, the ratio is attractive.
What this means for routing in May 2026
The open-weight coding tier in May 2026 has a shape we have not seen before. Qwen3 Coder Next sits at $0.11 with respectable SWE-Bench Verified and a small footprint. MiniMax M2.7 sits at $0.30 with the highest GDPval-AA on the open-weight board and a missing Verified score. Kimi K2.6 sits at $0.60 with the cleanest Verified numbers and a strong Terminal-Bench result. DeepSeek V4 Pro sits at $0.435 through May 31 with a promo that expires and then triples.
That is four open-weight options inside a 5.5x price band, all of them within 10 ELO points of each other on GDPval-AA. A year ago this tier had one credible entry. The routing playbook now is to use the cheap one (Qwen3 Coder Next) for high-volume function-level codegen, M2.7 for ML-engineering and multilingual work, Kimi K2.6 for Verified-sensitive agentic loops, and the closed frontier only for the workloads where Terminal-Bench, raw reasoning, or 1M context actually matter.
We track all of these on the TokenCost pricing page and the per-task math is in the calculator. The M2.7 model page lists the same pricing alongside the nearest competitors.
Sources
- MiniMax: M2.7 launch announcement - Release date March 18 2026, architecture, benchmark sheet
- Hugging Face: MiniMaxAI/MiniMax-M2.7 - Model card, parameter counts (229B total, 256 experts), license
- Artificial Analysis: MiniMax M2.7 - $0.30/$1.20 per 1M, GDPval-AA 1495 ELO, AA Intelligence Index 50
- OpenRouter: minimax/minimax-m2.7 - $0.279 input, $1.20 output, 197K context window
- MiniMax: text prompt caching - Cache hit feature, rate not surfaced on pricing page
- OpenRouter: Kimi K2.6 - Comparison pricing, SWE-Bench Verified 80.2
- DeepSeek: API pricing - V4 Pro promo $0.435/$0.87 through May 31, post-promo $1.74/$3.48
- Anthropic: Claude pricing - Opus 4.7 $5/$25 per 1M, Terminal-Bench 2 78.2